

Most Downloaded November 30, 2021
Authors
L. Ruff, J. R. Kauffmann, R. A. Vandermeulen, G. Montavon, W. Samek, M. Kloft, T. G. Dietterich, and K.-R. Müller
Abstract
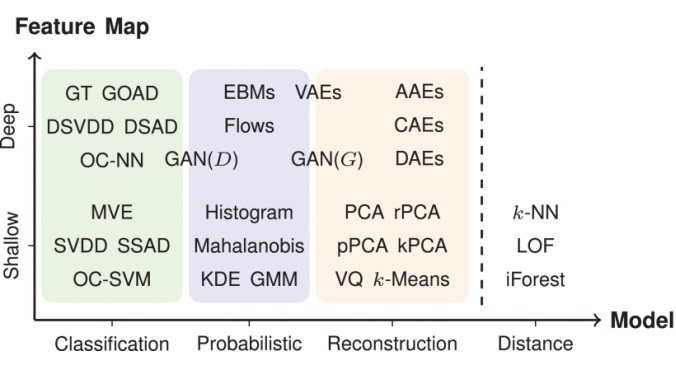
Deep learning approaches to anomaly detection (AD) have recently improved the state of the art in detection performance on complex data sets, such as large collections of images or text. These results have sparked a renewed interest in the AD problem and led to the introduction of a great variety of new methods. With the emergence of numerous such methods, including approaches based on generative models, one-class classification, and reconstruction, there is a growing need to bring methods of this field into a systematic and unified perspective. In this review, we aim to identify the common underlying principles and the assumptions that are often made implicitly by various methods. In particular, we draw connections between classic “shallow” and novel deep approaches and show how this relation might cross-fertilize or extend both directions. We further provide an empirical assessment of major existing methods that are enriched by the use of recent explainability techniques and present specific worked-through examples together with practical advice. Finally, we outline critical open challenges and identify specific paths for future research in AD.